ChatGPTを使った内部文書問い合わせ検証 1. 導入編
2023.10.16

はじめに
こんにちは。ビーンズラボの平良です。
2022年11月に公開されたChatGPTは、公開からわずか2ヶ月でアクティブユーザーが1億人に達し、今や多くの人々にとって身近な存在となりました。
ビジネス利用の観点からは、ChatGPTの高い言語能力を利用して「会社内部の資料への問い合わせにChatGPTが応答するチャットボット」が代表例として挙げられます。
「ChatGPTは凄い」という漠然としたイメージはあるものの、実際にChatGPTで何をどこまでできるのか、その強みや課題、工夫点について、意外とよくわからない部分は多くあります。本シリーズでは、代表的な活用例であるチャットボットの様々な検証を通して、ChatGPTの実際の姿を少しでも深く探ることができればと考えています。
シリーズ最初の本記事では、導入として、「会社内部の資料への問い合わせにChatGPTが応答するチャットボット」がどのような仕組みで成り立っているのかについて簡単に紹介したいと思います。
「会社内部の資料への問い合わせにChatGPTが応答するチャットボット」の仕組み
ビジネス利用の際に最初に乗り越えないといけない課題が以下です。
- ChatGPT自体に新しい知識を学ばせる方法がない(*) 当然のことながら素のChatGPTは会社の内部資料の知識を持っていません。
- ChatGPTには一度に入力できる文字数制限があり、そこまで大きくないことから、通常、一度に会社内部の書類群をすべて入れることは不可能 仮に入力制限長が存在せずすべて一度に入られたとしても精度面・コスト面から大きな問題がある
- 回答出力にもっともらしい嘘(ハルシネーション)が混ざることがある
現在、上記の各課題への一般的な対応策は以下の通りとなっています。
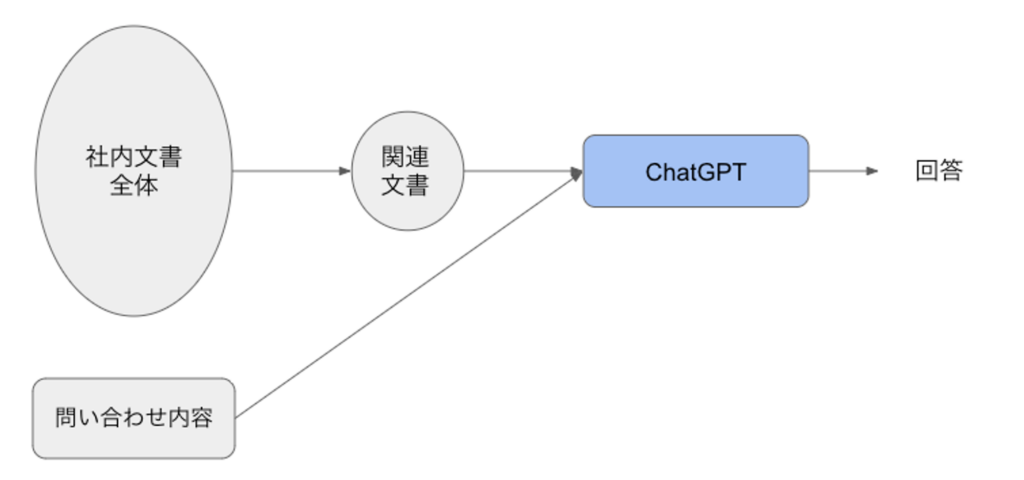
- 「この資料を参照して問い合わせに答えなさい」の形で”資料内容”と”問い合わせ内容”とを同時に与えると、ChatGPTはまるで社内文書の知識を持っているかのような回答を行うことが可能となる。
- 書類全体から問い合わせ内容と関連度の高い内容をまず絞り込み(下図の「関連文書」)、その絞った内容のみをChatGPTに与える。絞った内容でも一度で入りきれないときは分割して与える。
- 関連文書にある情報のみから答えるようChatGPTに指示をし、なるべくChatGPT自身が持っている知識を使わせないようにする。
卑近な喩えにはなりますが、要するに「適切なカンニングペーパーを用意できれば、本人に知識がなくてもテストに答えられる」といった仕組みです。
データセットについて
まず、本シリーズで取り上げる検証のため、沖縄県立図書館の公式サイト(https://www.library.pref.okinawa.jp/index.html)を利用させていただき、1ページ分の記事情報を1つのテキストファイルとした90件ほどの小粒のデータセットを作成しました。(本シリーズの検証利用のみが目的のためデータセットとしての公開予定はありません)
沖縄県立図書館の情報を利用した理由は、実際のビジネス文書に近い要素を多く含むためです。
- 注意事項、場所案内、各種サービスの利用条件や利用手順、申請書類案内などが含まれる
- テキストハイパーリンクやpdf、excel等の資料添付が多い
- 異なる記事にそれなりに近い話題が含まれることも多い 電子書籍利用サービスについて複数記事で触れられている等
【一例】沖縄県立図書館 – 協力貸出について https://www.library.pref.okinawa.jp/library/cat3/post-10.html
今後しばらくはこちらのデータセットを使って検証を行うこととします。
それでは、次から実際に、本記事で解説したような広く採用されている手法をベースに検証した内容を紹介していきます。
(*)2023年8月23日、OpenAIはChatGPTをファインチューニングする機能を公開しました(https://openai.com/blog/gpt-3-5-turbo-fine-tuning-and-api-updates)。それだけでチャットボットに求められる知識を身につけることは現実的ではないと現時点で考えていますが、それでも精度改善効果は見込めるはずなので、今後、可能であれば本シリーズで取り上げられたらと思います。
システム開発・保守、導入支援など、
お気軽にご相談ください